问题引入
- 计算机中存储信息的最小单元是一个字节即 8 个 bit,所以能表示的字符范围是 0~255 个
- 人类要表示的符号太多,无法用一个字节来完全表示
- 要解决这个矛盾必须需要一个新的数据结构 char,从 char 到 byte 必须编码
常见的编码格式
ASCII
ASCII 码,总共有 128 个,用一个字节的低 7 位表示,031 是控制字符如换行回车删除等;32126 是打印字符,可以通过键盘输入并且能够显示出来。ISO-8859-1
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。GB2312
它的全称是《信息交换用汉字编码字符集基本集》,它是双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字。GBK
全称叫《汉字内码扩展规范》,是国家技术监督局为 windows95 所制定的新的汉字内码规范,它的出现是为了扩展 GB2312,加入更多的汉字,它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。GB18030
全称是《信息交换用汉字编码字符集》,是我国的强制标准,它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。UTF-8
UTF-16 统一采用两个字节表示一个字符,虽然在表示上非常简单方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的今天,这样会增大网络传输的流量,而且也没必要。而 UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以是由 1~6 个字节组成。
UTF-8 有以下编码规则:- 如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
- 如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
- 如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节
- 如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
Java中的编解码
解码:字节->字符 编码:字符->字节
IO中的编解码
根据处理数据类型的不同分为:字符流(byte) 字节流(char)
根据数据流向不同分为:输入流(读,外存->内存) 输出流(写,内存->外存)
字符流:Reader,Writer
字节流:InputStream, OutputStream
桥梁:InputStreamReader(字节->字符) OutputStreamWriter(字符->字节)
InputStreamReader具体的解码由 StreamDecoder 实现,将字节解码成字符,解码过程中必须由用户指定 Charset 格式。值得注意的是如果你没有指定 Charset,将使用本地环境中的默认字符集,例如在中文环境中将使用 GBK 编码。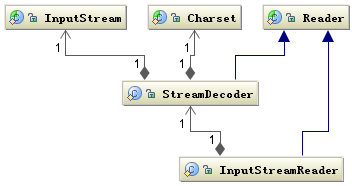
同样,OutputStreamWriter具体的编码由 StreamEncoder 实现,将字符编码成字节,编码格式和默认编码规则与解码是一致的。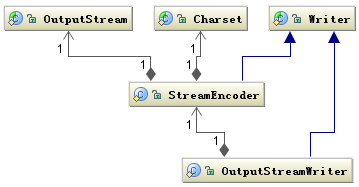
1 | String file = "c:/stream.txt"; |
内存中的编解码
在 Java 开发中除了 I/O 涉及到编码外,最常用的应该就是在内存中进行字符到字节的数据类型的转换,Java 中用 String 表示字符串,所以 String 类就提供转换到字节的方法,也支持将字节转换为字符串的构造函数。如下代码示例:
1 | String s = "这是一段中文字符串"; |
另外一个是已经被被废弃的 ByteToCharConverter 和 CharToByteConverter 类,它们被 Charset 类取代。Charset 提供 encode 与 decode 分别对应 char[] 到 byte[] 的编码和 byte[] 到 char[] 的解码。如下代码所示:
1 | Charset charset = Charset.forName("UTF-8"); |
Java中具体的编解码实例
1 | public class IOTest { |
打印结果如下
1 | -------- char[] -------- |
ISO-8859-1
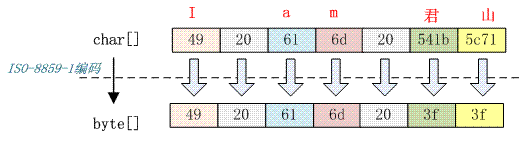
7 个 char 字符经过 ISO-8859-1 编码转变成 7 个 byte 数组,ISO-8859-1 是单字节编码,中文“君山”被转化成值是 3f 的 byte。3f 也就是“?”字符,所以经常会出现中文变成“?”很可能就是错误的使用了 ISO-8859-1 导致的。中文字符经过 ISO-8859-1 编码会丢失信息,通常我们称之为“黑洞”,它会把不认识的字符吸收掉。由于现在大部分基础的 Java 框架或系统默认的字符集编码都是 ISO-8859-1,所以很容易出现乱码问题。GB2312
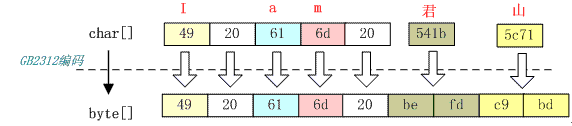
GB2312 字符集有一个 char 到 byte 的码表,不同的字符编码就是查这个码表找到与每个字符的对应的字节,然后拼装成 byte 数组。如果查到的码位值大于 oxff 则是双字节,否则是单字节。双字节高 8 位作为第一个字节,低 8 位作为第二个字节GBK
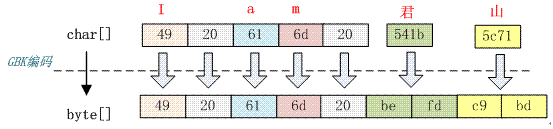
与 GB2312 编码的结果是一样的,由此可以得出 GBK 编码是兼容 GB2312 编码的,它们的编码算法也是一样的。不同的是它们的码表长度不一样,GBK 包含的汉字字符更多。所以只要是经过 GB2312 编码的汉字都可以用 GBK 进行解码,反过来则不然。UTF-16

用 UTF-16 编码将 char 数组放大了一倍,单字节范围内的字符,在高位补 0 变成两个字节,中文字符也变成两个字节。从 UTF-16 编码规则来看,仅仅将字符的高位和地位进行拆分变成两个字节。特点是编码效率非常高,规则很简单,由于不同处理器对 2 字节处理方式不同,Big-endian(高位字节在前,低位字节在后)或 Little-endian(低位字节在前,高位字节在后)编码,所以在对一串字符串进行编码是需要指明到底是 Big-endian 还是 Little-endian,所以前面有两个字节用来保存 BYTE_ORDER_MARK 值。(UTF16打印结果中的前两个字节fe ff,因为在Windows平台下默认的Unicode编码为Little-endian的UTF-16)UTF-16 是用定长 16 位(2 字节)来表示的 UCS-2 或 Unicode 转换格式,通过代理对来访问 BMP 之外的字符编码。UTF-8

UTF-16 虽然编码效率很高,但是对单字节范围内字符也放大了一倍,这无形也浪费了存储空间,另外 UTF-16 采用顺序编码,不能对单个字符的编码值进行校验,如果中间的一个字符码值损坏,后面的所有码值都将受影响。而 UTF-8 这些问题都不存在,UTF-8 对单字节范围内字符仍然用一个字节表示,对汉字采用三个字节表示。
UTF-8 编码与 GBK 和 GB2312 不同,不用查码表,所以在编码效率上 UTF-8 的效率会更好,所以在存储中文字符时 UTF-8 编码比较理想。
几种编码格式的比较
对中文字符后面四种编码格式都能处理,GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。