硬件内存架构
现代计算机硬件架构的简单图示: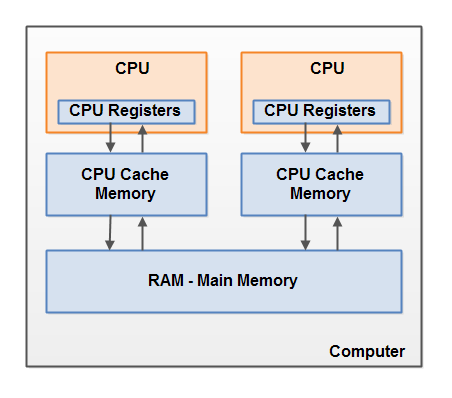
一个现代计算机通常由两个或者多个CPU。其中一些CPU还有多核。从这一点可以看出,在一个有两个或者多个CPU的现代计算机上同时运行多个线程是可能的。每个CPU在某一时刻运行一个线程是没有问题的。这意味着,如果你的Java程序是多线程的,在你的Java程序中每个CPU上一个线程可能同时(并发)执行。
每个CPU都包含一系列的寄存器,它们是CPU内内存的基础。CPU在寄存器上执行操作的速度远大于在主存上执行的速度。这是因为CPU访问寄存器的速度远大于主存。
每个CPU可能还有一个CPU缓存层。实际上,绝大多数的现代CPU都有一定大小的缓存层。CPU访问缓存层的速度快于访问主存的速度,但通常比访问内部寄存器的速度还要慢一点。一些CPU还有多层缓存,但这些对理解Java内存模型如何和内存交互不是那么重要。只要知道CPU中可以有一个缓存层就可以了。
一个计算机还包含一个主存。所有的CPU都可以访问主存。主存通常比CPU中的缓存大得多。
通常情况下,当一个CPU需要读取主存时,它会将主存的部分读到CPU缓存中。它甚至可能将缓存中的部分内容读到它的内部寄存器中,然后在寄存器中执行操作。当CPU需要将结果写回到主存中去时,它会将内部寄存器的值刷新到缓存中,然后在某个时间点将值刷新回主存。
当CPU需要在缓存层存放一些东西的时候,存放在缓存中的内容通常会被刷新回主存。CPU缓存可以在某一时刻将数据局部写到它的内存中,和在某一时刻局部刷新它的内存。它不会再某一时刻读/写整个缓存。通常,在一个被称作“cache lines”的更小的内存块中缓存被更新。一个或者多个缓存行可能被读到缓存,一个或者多个缓存行可能再被刷新回主存。
内存数据存储
提出问题:指令和数据都存放在内存中,那么CPU怎么区分是指令还是数据呢?
这是一个很大的问题,就简单从这两个方面来分析
- 从时间上
取指令事件发生在指令周期的第一个CPU周期中,即发生在“取指令”阶段,指令周期的长短与指令的复杂程度有关,而取数据事件发生在指令周期的后面几个CPU周期中,即发生在“执行指令”阶段。 - 从空间上
如果取出的代码是指令,那么一定送往指令寄存器,如果取出的代码是数据,那么一定送往运算器。例如:8086采用分段存储管理方式,CPU将CS:IP指向的内存单元的内容看作指令。因为任何时候,CPU用CS:IP合成指令的物理地址,在执行指令的周期,CPU读DS段去找数据。
于是有这样的内存模型: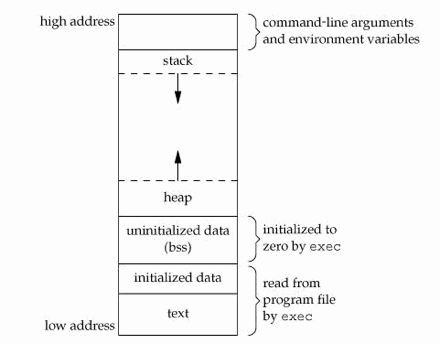
每当一个程序被执行,系统就要为它开启一个进程,并且为它分配内存。从低址区到高址区,分成几个不同的区域。 - 低址:存放程序代码本身。(例如8086的CS寄存器中保存的段地址指向的位置)
- 次低址:存放全局变量,无论是初始化的还是未初始化的。
- 中址:就是堆(Heap)和堆栈(Stack)的区域。用来储存进程运行过程中产生的变量。
- 最高址:为系统额外预留的空间。我们无法操作。
stack(堆栈)
从高址区往下延展。用来存储Scoped Variable(限域变量)。简单说就是已知存储空间以及生命周期的变量。为什么stack效率高呢?因为变量大小确定,都是紧挨着储存的,在堆栈中创建和释放储存空间只要一条汇编语言,分别是将栈顶指针向下和向上移动。而stack本身又是LIFO(Last in First out)的,所以效率极高。
heap(堆)
从较低地址区往上移动。heap是个动态内存池。从下面的图我们看的很清楚,heap不像stack那样是数据是连续的,而且使用LIFO机制。heap的数据是不连续的,动态随便乱贴的。创建和释放效率都不高。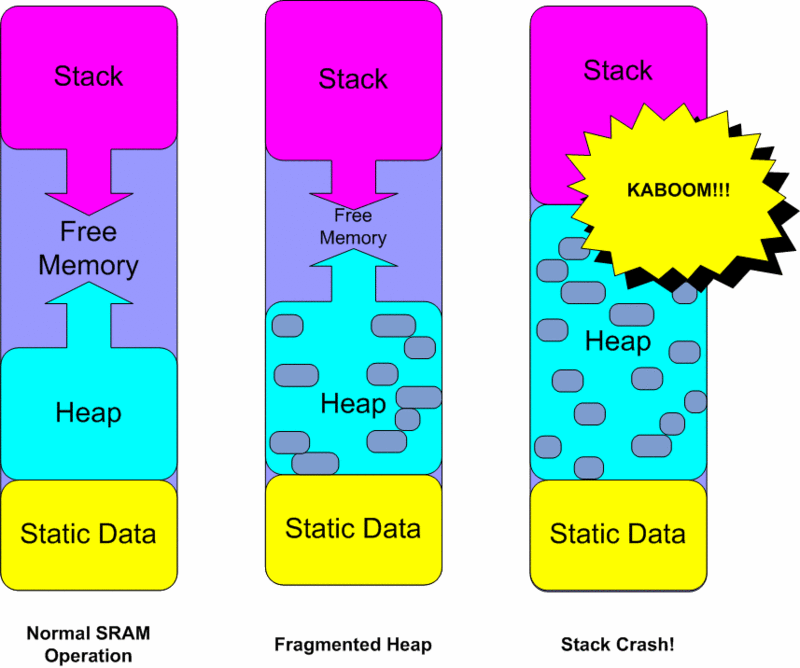
至于是大端存储还是小端存储的方式在这里就不做过多的讨论了: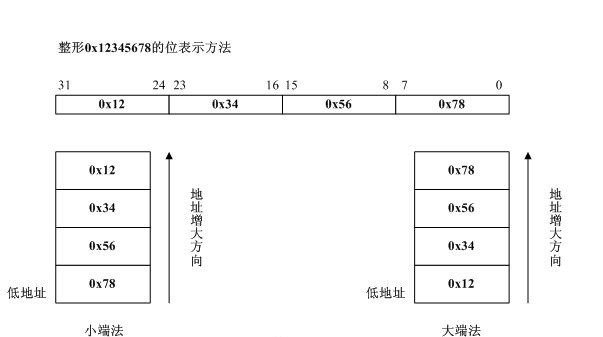
Java内存模型内部原理
Java内存模型把Java虚拟机内部划分为
- 线程栈(堆栈,Stack == Thread Stack)
- 堆(Heap)
“引用”存放在Stack中,Object存放在Heap中
这张图演示了Java内存模型的逻辑视图。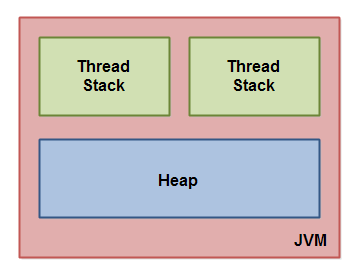
每一个运行在Java虚拟机里的线程都拥有自己的线程栈。这个线程栈包含了这个线程调用的方法当前执行点相关的信息。一个线程仅能访问自己的线程栈。一个线程创建的本地变量对其它线程不可见,仅自己可见。即使两个线程执行同样的代码,这两个线程任然在在自己的线程栈中的代码来创建本地变量。因此,每个线程拥有每个本地变量的独有版本。
所有原始类型的本地变量都存放在线程栈上,因此对其它线程不可见。一个线程可能向另一个线程传递一个原始类型变量的拷贝,但是它不能共享这个原始类型变量自身。
堆上包含在Java程序中创建的所有对象,无论是哪一个对象创建的。这包括原始类型的对象版本。如果一个对象被创建然后赋值给一个局部变量,或者用来作为另一个对象的成员变量,这个对象任然是存放在堆上。
示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// 假设有两个线程Thread1、Thread2
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
// 本地变量,存放在Thread Stack中
int localVariable1 = 45;
// 对象Object3存放在Heap中,引用存放在Thread Stack中
MySharedObject localVariable2 = MySharedObject.sharedInstance;
methodTwo();
}
public void methodTwo() {
// 对象Object1、Object5存放在Heap中,引用存放在Thread Stack中
Integer localVariable1 = new Integer(99);
}
}
public class MySharedObject {
// 指向MyShareObject实例的静态变量(Object3),随着类定义存放在Heap中
// 这个对象可以被持有该对象引用(localVariable2)的线程T1、T2访问
// 如果调用Object3的同一个方法,T1、T2会创建一个该对象本地成员变量的私有拷贝
public static final MySharedObject sharedInstance = new MySharedObject();
// 存放在Heap中的成员变量引用(Object1、Object5)
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
// 成员变量存放在Heap中
public long member1 = 12345;
public long member1 = 67890;
}
下面这张图演示了调用栈和本地变量存放在线程栈上,对象存放在堆上。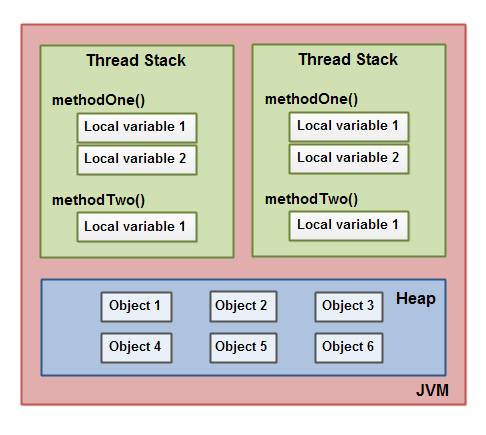
Java内存模型和硬件内存架构之间的桥接
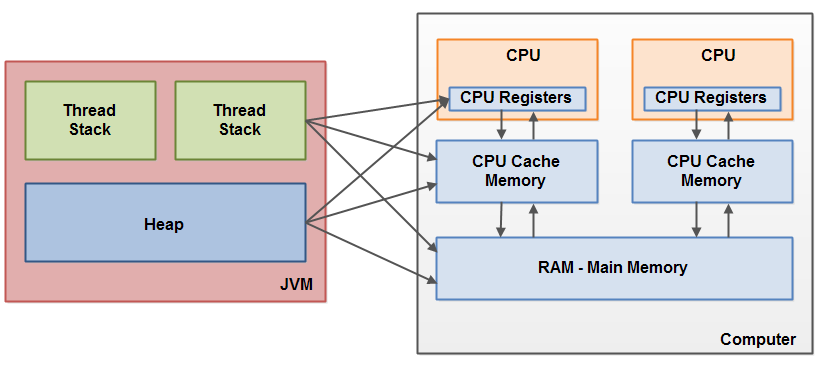
Java内存模型模拟了硬件内存架构,如果把Heap比作内存,把Thread Stack比作多个处理器与缓存层的话,当有多个线程时,每个Stack从内存中将数据拷贝,变更以后再写回内存时就会出现数据不一致的情况。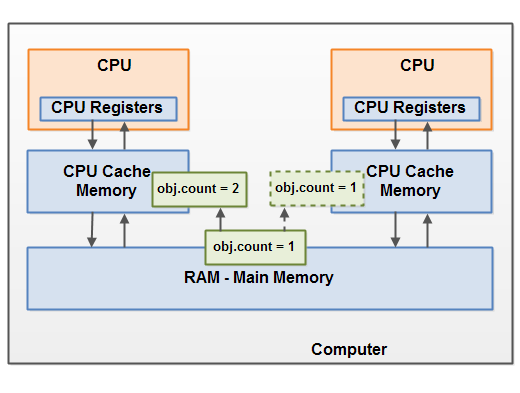
Java中的volatile关键字。volatile关键字可以保证直接从主存中读取一个变量,如果这个变量被修改后,总是会被写回到主存中去。但这只能保证用volatile读到的数据是内存中最新的,但在copy到Thread Stack以后其他线程再改变数据就会出现问题,这就是存在竞争。
为了解决这个问题,可以使用Java同步块。一个同步块可以保证在同一时刻仅有一个线程可以进入代码的临界区(读取临界资源)。同步块还可以保证代码块中所有被访问的变量将会从主存中读入,当线程退出同步代码块时,所有被更新的变量都会被刷新回主存中去,不管这个变量是否被声明为volatile。
参考: