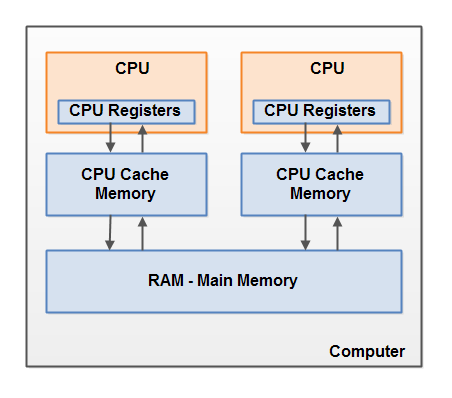
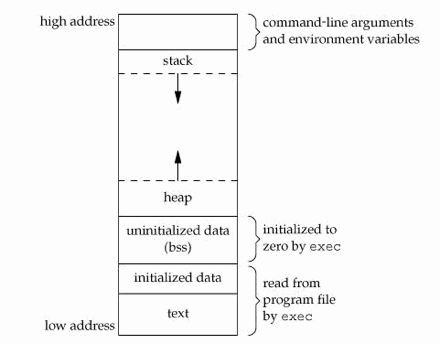
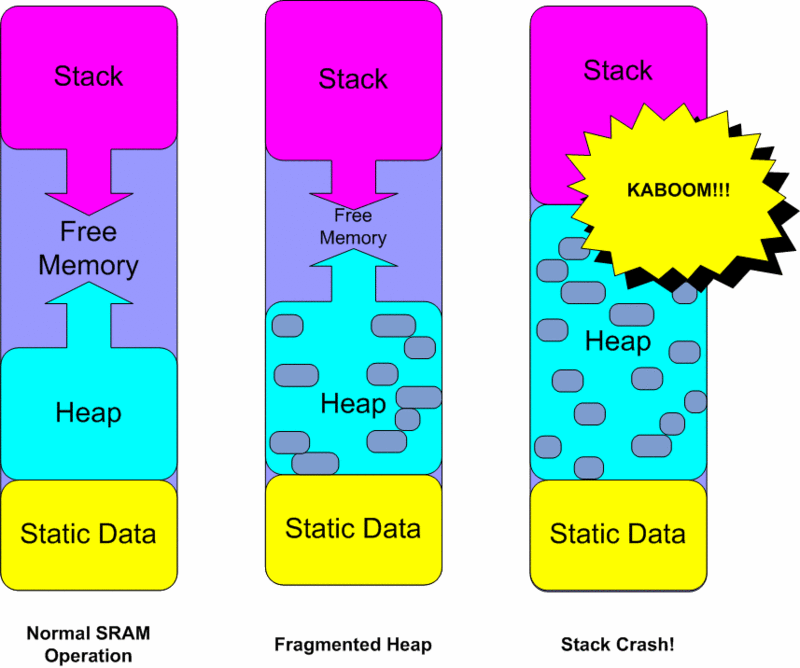
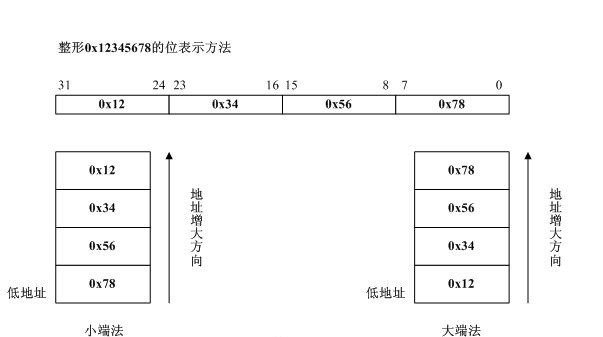
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| // 采用第二种思路
public class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int m = nums1.length;
int n = nums2.length;
int total = m + n;
// 奇数
if (total % 2 != 0) {
return findKth(nums1, 0, m-1, nums2, 0, n-1, total/2 + 1); // 第total/2+1个元素
} else {
double x = findKth(nums1, 0, m-1, nums2, 0, n-1, total/2);
double y = findKth(nums1, 0, m-1, nums2, 0, n-1, total/2 + 1);
return (x + y) / 2;
}
}
// 指针从1开始计数
private double findKth(int[] a, int aLeft, int aRight, int[] b, int bLeft, int bRight, int k) {
int m = aRight - aLeft + 1; // 当前a的扫描长度
int n = bRight - bLeft + 1; // 当前b的扫描长度
if (m > n)
return findKth(b, bLeft, bRight, a, aLeft, aRight, k);
if (m == 0)
return b[k-1];
if (k == 1)
return Math.min(a[aLeft], b[bLeft]);
int partA = Math.min(m, k/2); // a的指针偏移量
int partB = k - partA; // a指针偏移了partA,在合并后的数组中,b指针偏移k-partA
// a和b哪个偏移后的数值小,说明Kth大于哪个,证明见下文。则可忽略小于偏移量的那些元素。
if (a[aLeft + partA - 1] > b[bLeft + partB - 1])
return findKth(a, aLeft, aRight, b, bLeft+partB, bRight, k-partB);
else if (a[aLeft + partA - 1] < b[bLeft + partB -1])
return findKth(a, aLeft+partA, aRight, b, bLeft, bRight, k-partA);
else
// a[aLeft+partA-1] == b[bLeft+partB-1],找到Kth
return a[aLeft + partA - 1];
}
}
|