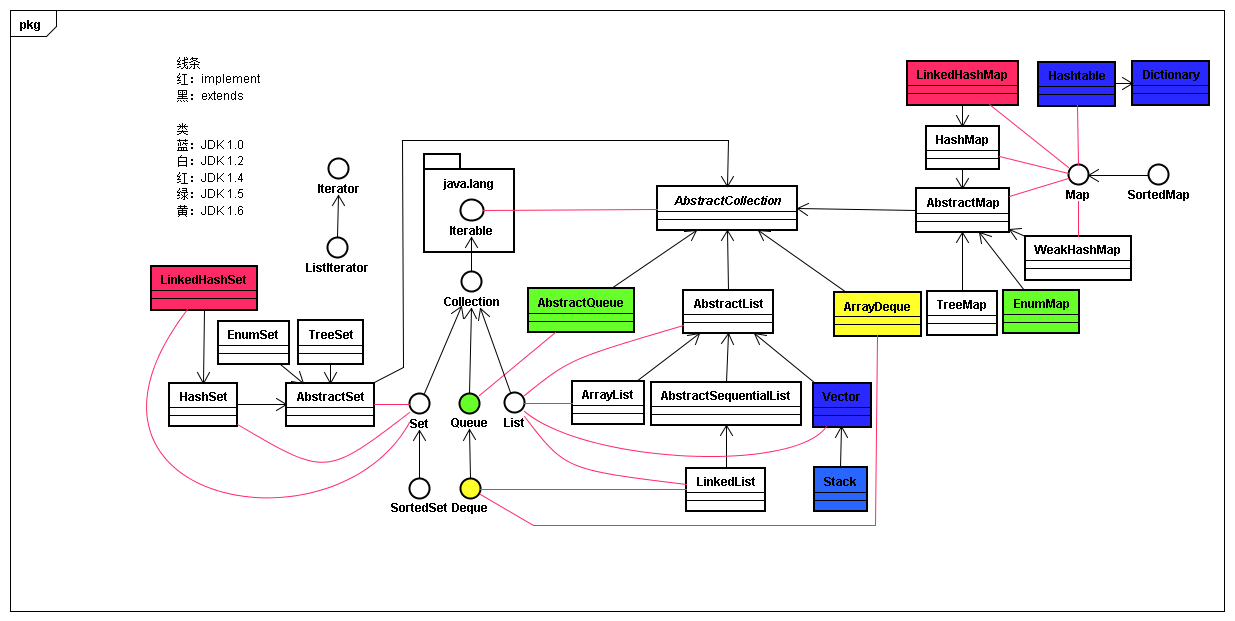
private void fastRemove(int index) { modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work }
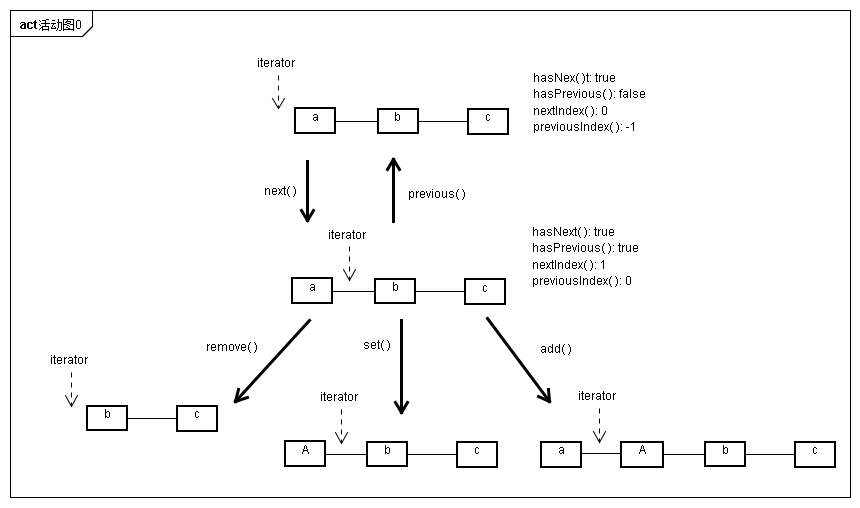
private class Itr implements Iterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount;
public boolean hasNext() { return cursor != size; }
@SuppressWarnings("unchecked") public E next() { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; }
public void remove() { if (lastRet < 0) throw new IllegalStateException(); checkForComodification();
@Override @SuppressWarnings("unchecked") public void forEachRemaining(Consumer<? super E> consumer) { Objects.requireNonNull(consumer); final int size = ArrayList.this.size; int i = cursor; if (i >= size) { return; } final Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } while (i != size && modCount == expectedModCount) { consumer.accept((E) elementData[i++]); } // update once at end of iteration to reduce heap write traffic cursor = i; lastRet = i - 1; checkForComodification(); }
final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }
public int indexOf(Object o) { if (o == null) { for (int i = 0; i < size; i++) if (elementData[i] == null) return i; } else { for (int i = 0; i < size; i++) if (o.equals(elementData[i])) return i; } return -1; } public int lastIndexOf(Object o) { if (o == null) { for (int i = size-1; i >= 0; i--) if (elementData[i]==null) return i; } else { for (int i = size-1; i >= 0; i--) if (o.equals(elementData[i])) return i; } return -1; }
get(int index),得到指定位置的元素,复杂度O(1)
1 2 3 4 5
public E get(int index) { rangeCheck(index); // 检查索引越界情况
return elementData(index); }
set(int index, E element),替换指定位置的元素,复杂度O(1)
1 2 3 4 5 6 7
public E set(int index, E element) { rangeCheck(index); // 检查索引越界情况
E oldValue = elementData(index); elementData[index] = element; return oldValue; }
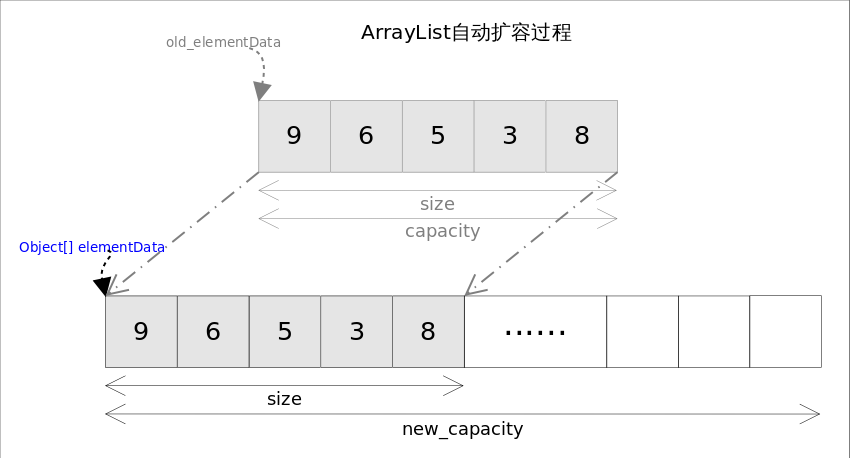
private void grow(int minCapacity) { int oldCapacity = elementData.length; // 扩容为原来的1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容后仍不够 if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
add(int index, E element),在指定位置添加元素,复杂度O(n) 需要将该位置后的所有元素向后移动一位,复杂度取决于数组规模
1 2 3 4 5 6 7 8
public void add(int index, E element) { rangeCheckForAdd(index);
public boolean remove(Object o) { if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; }
addAll() 一次性添加多个元素,根据位置不同也有两个把本,一个是在末尾添加的 addAll(Collection<? extends E> c) 方法,一个是从指定位置开始插入的 addAll(int index, Collection<? extends E> c) 方法。跟 add() 方法类似,在插入之前也需要进行空间检查,如果需要则自动扩容;如果从指定位置插入,也会存在移动元素的情况。 addAll() 的时间复杂度不仅跟插入元素的多少有关,也跟插入的位置相关。
removeAll(Collection<?> c) 删除指定collection中包含的所有元素,即求两个集合的差集,A-B。
retainAll(Collection<?> c) 保留指定collection中包含的所有元素,即求两个集合的交集,A∩B。